
Scenario 3: Initial rate analysis with and without Tween
Contents
Scenario 3: Initial rate analysis with and without Tween¶
Dataset provided by Alexander Behr, Julia Grühn and Katrin Rosenthal (Department of Biochemical and ChemicalEngineering, TU Dortmund University, Dortmund, Germany)
The aim of the initial rate analysis is to investigate the influence of Tween 80 on the oxidation of ABTS by Trametes versicolor laccase. The dataset contains measurements of the product concentration for different initial substrate concentrations, first with 1% Tween 80, then without Tween 80. The experiment was conducted in a straight tube reactor. In the course of the project, experiments in a spiral tube reactor should be performed, and those will only contain two data points per measurement, one at the beginning and one at the end of the reactor. Therefore, in the absence of time-course data, only initial rate analysis can be performed. In preparation for this, an initial rate analysis is done in this scenario.
Imports¶
First, all necessary Python packages must be installed and imported.
This step is the same for all scenarios and differs only in the used python packages.
If you run this notebook with Binder, you don’t have to install anything. Binder takes care of this.
If you run this notebook locally, make sure you have all Packages installed. All needed packages with the used version can be found in the requirements.txt in the root GitHub directory (not in \book).
import os
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from lmfit import minimize, Parameters, report_fit
from pyenzyme import EnzymeMLDocument
Reading EnzymeML with PyEnzyme software¶
In order to read the EnzymeML document and access its content with the PyEnzyme software, the file path is defined.
If you want to run this Jupyter Notebook locally, make sure you have the same folder structure or change the path accordingly.
When running the following code cell, the EnzymeML document is saved in the enzmlDoc variable, and an overview is printed below.
path = '../../data/Rosenthal_Measurements_orig.omex'
# check for correct file path and file extension:
if os.path.isfile(path) and os.path.basename(path).lower().endswith('.omex'):
enzmlDoc = EnzymeMLDocument.fromFile(path)
enzmlDoc.printDocument(measurements=True)
else:
raise FileNotFoundError(
f'Couldnt find file at {path}.'
)
Laccase_STR_Kinetic
>>> Reactants
ID: s0 Name: ABTS reduced
ID: s1 Name: oxygen
ID: s2 Name: ABTS oxidized
ID: s3 Name: Tween 80
>>> Proteins
ID: p0 Name: Laccase
>>> Complexes
>>> Reactions
ID: r0 Name: ABTS oxidation
>>> Measurements
ID Species Conc Unit
===================================
m0 p0 3.525 umole / l
m0 s0 36.450 umole / l
m0 s1 204 umole / l
m0 s2 0 umole / l
m0 s3 8.090 mmole / l
m1 p0 3.525 umole / l
m1 s0 91.130 umole / l
m1 s1 204 umole / l
m1 s2 0 umole / l
m1 s3 8.090 mmole / l
m2 p0 3.525 umole / l
m2 s0 182.260 umole / l
m2 s1 204 umole / l
m2 s2 0 umole / l
m2 s3 8.090 mmole / l
m3 p0 3.525 umole / l
m3 s0 364.510 umole / l
m3 s1 204 umole / l
m3 s2 0 umole / l
m3 s3 8.090 mmole / l
m4 p0 3.525 umole / l
m4 s0 729.020 umole / l
m4 s1 204 umole / l
m4 s2 0 umole / l
m4 s3 8.090 mmole / l
m5 p0 3.525 umole / l
m5 s0 911.280 umole / l
m5 s1 204 umole / l
m5 s2 0 umole / l
m5 s3 8.090 mmole / l
m6 p0 3.525 umole / l
m6 s0 36.450 umole / l
m6 s1 204 umole / l
m6 s2 0 umole / l
m6 s3 0 mmole / l
m7 p0 3.525 umole / l
m7 s0 91.130 umole / l
m7 s1 204 umole / l
m7 s2 0 umole / l
m7 s3 0 mmole / l
m8 p0 3.525 umole / l
m8 s0 182.260 umole / l
m8 s1 204 umole / l
m8 s2 0 umole / l
m8 s3 0 mmole / l
m9 p0 3.525 umole / l
m9 s0 364.510 umole / l
m9 s1 204 umole / l
m9 s2 0 umole / l
m9 s3 0 mmole / l
m10 p0 3.525 umole / l
m10 s0 729.020 umole / l
m10 s1 204 umole / l
m10 s2 0 umole / l
m10 s3 0 mmole / l
m11 p0 3.525 umole / l
m11 s0 911.280 umole / l
m11 s1 204 umole / l
m11 s2 0 umole / l
m11 s3 0 mmole / l
The overview showed which reactant corresponds to which ID.
Each measurement consists of four reactants and one protein (p0).
From the measurement information we can derive that the concentration of ABTS reduced (s0) and Tween 80 (s3) was varied.
All concentrations, except for Tween, were given in the same units; therefore, they don’t have to be converted later on.
Next, one measurement is exemplarily examined.
# Fetch the measurement and inspect the scheme
measurement = enzmlDoc.getMeasurement('m0')
measurement.printMeasurementScheme()
>>> Measurement m0: ABTS (1%) 1
s0 | initial conc: 36.45 umole / l | #replicates: 0
s1 | initial conc: 204.0 umole / l | #replicates: 0
s2 | initial conc: 0.0 umole / l | #replicates: 2
s3 | initial conc: 8.09 mmole / l | #replicates: 0
p0 | initial conc: 3.525 umole / l | #replicates: 0
The measurement shows that only the product ABTS oxidized (s2) was measured.
In this case, the two replicates per measurement correspond to one absorbance and one concentration measurement.
Data preparation¶
To visualise and model the data, it must first be extracted and prepared.
All relevant data such as the initial concentrations and time-course data are extracted and saved for each measurement in a dictionary.
The outer data-structure dataDict is a dictionary to distinguish between measurements with and without Tween 80.
For convenient visualisation, a second dictionary visualisationData contains only the time-course data.
Since the absorbance has already been converted to concentration, only the concentration time-course data is extracted and modelled, for an easier comparison of the results.
# initialise data-structure to store experimental data
dataDict = {
'tween': [],
'noTween': []
}
visualisationData = {
'tween': [],
'noTween': []
}
# time and units
time = np.array(enzmlDoc.getMeasurement('m0').global_time, float)
timeUnit = enzmlDoc.getMeasurement('m0').global_time_unit
concentrationUnit = ''
# go through all measurements:
for measurement in enzmlDoc.measurement_dict.values():
measurementData = {
'p0': measurement.getProtein('p0').init_conc,
's0': measurement.getReactant('s0').init_conc,
's1': measurement.getReactant('s1').init_conc,
's2': measurement.getReactant('s2').init_conc,
's3': measurement.getReactant('s3').init_conc,
'measured': []
}
# get replicates with time course data:
reactant = measurement.getReactant('s2')
concentrationUnit = reactant.unit
for replicate in reactant.replicates:
if replicate.data_type == 'conc':
measurementData['measured'].append(replicate.data)
# distinguish between measurements with and without tween
if measurement.getReactant('s3').init_conc == 0.0:
dataDict['noTween'].append(measurementData)
visualisationData['noTween'].append(measurementData['measured'])
else:
dataDict['tween'].append(measurementData)
visualisationData['tween'].append(measurementData['measured'])
Visualisation of time-course data¶
All time-course data is visualised with the Python library Matplotlib.
To save the figure as SVG uncomment the plt.savefig(...) code line.
# define colors for all visualisations
colors = ['#f781bf','#984ea3','#ff7f00','#ffff33','#a65628','#4daf4a']
reaction_name = enzmlDoc.getReaction('r0').name
# plot time course data with matplotlib
fig = plt.figure()
gs = fig.add_gridspec(1, 2, wspace = 0)
(ax1, ax2) = gs.subplots(sharey = True)
fig.suptitle('Measurement '+reaction_name)
for i in range(len(visualisationData['tween'])):
ax1.plot(time, visualisationData['noTween'][i][0], 'o', ms=3, color = colors[i])
ax1.set(title = 'without Tween 80', xlabel = 'time ['+timeUnit+']', \
ylabel = 'concentration ['+concentrationUnit+']')
ax2.plot(time, visualisationData['tween'][i][0], 'o', ms=3, color = colors[i])
ax2.set(title = 'with Tween 80', xlabel = 'time ['+timeUnit+']')
ax1.set_ylim(ymin=0)
ax2.set_ylim(ymin=0)
# save as svg
# plt.savefig('time-course.svg', bbox_inches='tight')
plt.show()
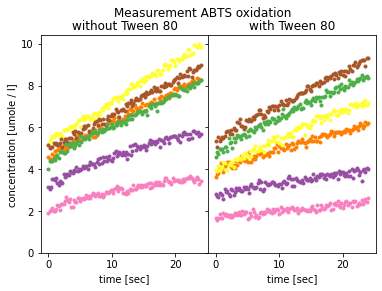
The visualisation shows that the time-course data for the product does not start at 0, as stated in the EnzymeML document in the initial concentration field. This indicates that either the measurement did not start immediately and a part of the substrate was already converted, or only the linear part was transferred from the original data into the EnzymeML document.
Computation of initial rates¶
Initial rates for the different substrate concentrations are calculated with linear regression by the Python library SciPy and added to the allData dictionary.
Simultaneously curves from linear regression are plotted together with measurements to get a visual impression of the fit goodness.
The regression was done over the whole time-course, including all available data points. Alternatively, only a part could have been defined for the linear regression as in Scenario 2.
# Function returning a curve with the initial rate as the slope for visualisation
def initialRateCurve(time, slope, intercept):
curve = slope*time+intercept
return curve
# Visualisation
fig = plt.figure()
gs = fig.add_gridspec(1, 2, wspace = 0)
(ax1, ax2) = gs.subplots(sharey = True)
fig.suptitle('Measurement '+reaction_name+' with initial rate curves')
i = 0
for measurementData in dataDict['noTween']:
# computation of initial rates with linear regression
slope, intercept, r, p, se = stats.linregress(time, measurementData['measured'][0])
measurementData['v'] = slope
# visualisation of time-course data and initial rate curves
ax1.plot(time, measurementData['measured'][0], 'o', ms=3, color = colors[i])
ax1.plot(time, initialRateCurve(time, slope, intercept), '-', linewidth=1, color='#e31a1c')
ax1.set(title = 'without Tween 80', xlabel = 'time ['+timeUnit+']', \
ylabel = 'concentration ['+concentrationUnit+']')
i += 1
i = 0
for measurementData in dataDict['tween']:
# computation of initial rates with linear regression
slope, intercept, r, p, se = stats.linregress(time, measurementData['measured'][0])
measurementData['v'] = slope
# visualisation of time-course data and initial rate curves
ax2.plot(time, measurementData['measured'][0], 'o', ms=3, color = colors[i])
ax2.plot(time, initialRateCurve(time, slope, intercept), '-', linewidth=1, color='#e31a1c')
ax2.set(title = 'with Tween 80', xlabel = 'time ['+timeUnit+']')
i += 1
ax1.set_ylim(ymin=0)
ax2.set_ylim(ymin=0)
# save as svg
# plt.savefig('time-course_with_slope.svg', bbox_inches='tight')
plt.show()
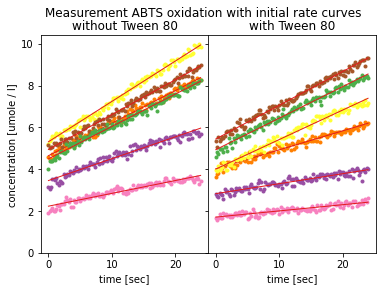
Plots of initial rates over ABTS concentrations.¶
For the modelling in the next step, an additional data point for the substrate concentration of zero is added. This data point is trivial but can help with the fit since this is an exact point without errors.
measurementData = dataDict['noTween'][0]
measurementDataNew = {
'p0': measurementData['p0'],
's0': 0.0,
's1': measurementData['s1'],
's2': measurementData['s2'],
's3': measurementData['s3'],
'v': 0.0,
'measured': []
}
dataDict['noTween'].insert(0,measurementDataNew)
measurementData = dataDict['tween'][0]
measurementDataNew = {
'p0': measurementData['p0'],
's0': 0.0,
's1': measurementData['s1'],
's2': measurementData['s2'],
's3': measurementData['s3'],
'v': 0.0,
'measured': []
}
dataDict['tween'].insert(0,measurementDataNew)
fig = plt.figure()
gs = fig.add_gridspec(1, 2, wspace = 0)
(ax1, ax2) = gs.subplots(sharey = True)
fig.suptitle('initial rates ')
for measurementData in dataDict['noTween']:
ax1.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
ax1.set(title = 'without Tween 80', ylabel ='initial rate [ '+concentrationUnit+'* 1/'+timeUnit+']', \
xlabel = 'ABTS concentration ['+concentrationUnit+']')
for measurementData in dataDict['tween']:
ax2.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
ax2.set(title = 'with Tween 80', xlabel = 'ABTS concentration ['+concentrationUnit+']')
# save as svg
# plt.savefig('initial-rates.svg', bbox_inches='tight')
plt.show()
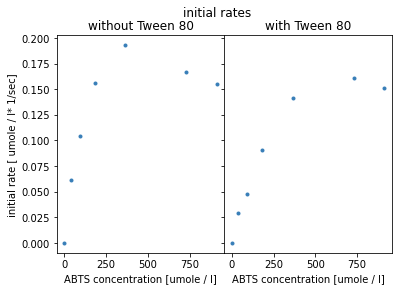
The visualisation shows an optimum curve, with decreasing initial rates for higher substrate concentrations. For the experiment with Tween, the optimum shifts to the right and initial rates are reduced for smaller substrate concentrations.
Modelling and parameter estimation¶
To model the data and perform parameter fitting, the models’ rate equations are defined as Python functions, along with a function to calculate the residual between the models and the previously computed initial rates.
In the following cell, two different models are defined. First the irreversible Michaelis-Menten kinetic, which is often used in biocatalysis for a first analysis. Katrin Rosenthal and her team also performed a Michaelis-Menten analysis with the Origin Pro software, which needs the initial rates as input, those were calculated in Excel.
The standard irreversible Michaelis-Menten kinetic results in a saturation, not an optimum, curve. Therefore, an extension of the Michaelis-Menten kinetic with substrate inhibition was implemented.
The extension was derived from the article [Sna16] on The Science Snail website.
Both models can be fitted either with v_max or k_cat. In this version, the modelling is done with v_max, but comments can be changed accordingly.
def irreversibleMichaelisMenten(kineticVariables, parameters):
'''
Rate equation according to Michaelis-Menten,
with the Michaelis-Menten constant K_M and k_cat as as parameters
Arguments:
kineticVariables: vector of variables: kineticVariables = [s0, p0]
parameters: parameters object from lmfit
'''
# ABTS:
s0 = kineticVariables[0]
# Enzyme:
p0 = kineticVariables[1]
#k_cat = parameters['k_cat'].value
v_max = parameters['v_max'].value
K_M = parameters['K_M'].value
#v = k_cat*p0*s0/(K_M+s0)
v = v_max*s0/(K_M+s0)
return v
def michaelisMentenWithSubstrateInhibition(kineticVariables, parameters):
'''
Rate equation extending Michaelis-Menten,
with substrate inhibition introducing an additional inhibition parameter K_i
Arguments:
kineticVariables: vector of variables: kineticVariables = [s0, p0]
parameters: parameters object from lmfit
'''
# ABTS:
s0 = kineticVariables[0]
# Enzyme:
p0 = kineticVariables[1]
#k_cat = parameters['k_cat'].value
v_max = parameters['v_max'].value
K_M = parameters['K_M'].value
K_i = parameters['K_i']
#v = k_cat*p0*s0/((K_M+s0)*(1+s0/K_i))
v = v_max*s0/((K_M+s0)*(1+s0/K_i))
return v
def residual(parameters, tween: str, kineticEquation):
'''
Residual function to compute difference between the model,
defined in the kineticEquation and the computed initial rates.
Arguments:
parameters: parameters object from lmfit
tween: key to select data with or without Tween 80
kineticEquation: function defining the kinetc model
'''
measurementsData = dataDict[tween]
residual = [0.0]*len(measurementsData)
for i in range(len(measurementsData)):
measurementData = measurementsData[i]
v_modeled = kineticEquation([measurementData['s0'],measurementData['p0']], parameters)
residual[i]=measurementData['v']-v_modeled
return residual
Results irreversible Michaelis-Menten¶
For each modelling step the a parameters object from the Python library lmfit is initialised.
The parameters are derived from curve-fitting, which is done by minimizing the least square error of the residual function.
params = Parameters()
#params.add('k_cat', value=0.6, min=0.0001, max=1000)
params.add('v_max', value=0.6, min=0.0001, max=1000)
params.add('K_M', value=100, min=0.0001, max=10000)
resultsMichaelisMentenNoTween = minimize(residual, params, \
args=('noTween', irreversibleMichaelisMenten), method='leastsq')
resultsMichaelisMentenTween = minimize(residual, params, \
args=('tween', irreversibleMichaelisMenten), method='leastsq')
Results for measurements without Tween
Lmfit provides a structured overview of the fit statistics such as used minimisation method and different quality criterion such as Akaike and Bayesian, together with statistics about the estimated parameters.
report_fit(resultsMichaelisMentenNoTween)
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 16
# data points = 7
# variables = 2
chi-square = 0.00188835
reduced chi-square = 3.7767e-04
Akaike info crit = -53.5257279
Bayesian info crit = -53.6339076
[[Variables]]
v_max: 0.18850416 +/- 0.01613198 (8.56%) (init = 0.6)
K_M: 60.0378698 +/- 23.4308038 (39.03%) (init = 100)
[[Correlations]] (unreported correlations are < 0.100)
C(v_max, K_M) = 0.768
Results for measurements with Tween
report_fit(resultsMichaelisMentenTween)
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 16
# data points = 7
# variables = 2
chi-square = 5.3985e-04
reduced chi-square = 1.0797e-04
Akaike info crit = -62.2909156
Bayesian info crit = -62.3990953
[[Variables]]
v_max: 0.20229660 +/- 0.01684044 (8.32%) (init = 0.6)
K_M: 219.502108 +/- 53.0418147 (24.16%) (init = 100)
[[Correlations]] (unreported correlations are < 0.100)
C(v_max, K_M) = 0.897
Visualisation of results
fig = plt.figure()
gs = fig.add_gridspec(1, 2, wspace = 0)
(ax1, ax2) = gs.subplots(sharey = True)
fig.suptitle('irrev. Michaelis-Menten kinetic ')
sNoTween = []
sTween = []
vNoTween = []
vTween = []
for measurementData in dataDict['noTween']:
ax1.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
sNoTween.append(measurementData['s0'])
vNoTween.append(irreversibleMichaelisMenten([measurementData['s0'],measurementData['p0']], \
resultsMichaelisMentenNoTween.params))
ax1.set(title = 'without Tween 80', ylabel ='initial rate [ '+concentrationUnit+'* 1/'+timeUnit+']', \
xlabel = 'ABTS concentration ['+concentrationUnit+']')
for measurementData in dataDict['tween']:
ax2.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
sTween.append(measurementData['s0'])
vTween.append(irreversibleMichaelisMenten([measurementData['s0'],measurementData['p0']], \
resultsMichaelisMentenTween.params))
ax2.set(title = 'with Tween 80', xlabel = 'ABTS concentration ['+concentrationUnit+']')
ax1.plot(sNoTween, vNoTween, '-', linewidth=1, color='#e31a1c')
ax2.plot(sTween, vTween, '-', linewidth=1, color='#e31a1c')
# save as svg
# plt.savefig('initial-rates_irrev_Michaelis_Menten.svg', bbox_inches='tight')
plt.show()
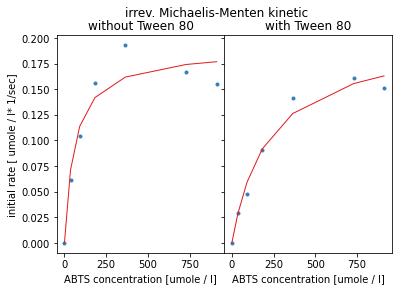
The visualisation shows the resulting curves from the estimated parameters in red. The Michaelis-Menten kinetic follows a saturation curve and therefore can not map the data-points showing an optimum curve.
In a meeting with Katrin Rosenthal the estimated K_M values from this Jupyter Notebook were compared to those estimated by the Origin Pro software.
Jupyter Notebook |
Origin Pro |
|
|---|---|---|
Without Tween |
60 +- 23 µM |
60 +- 26 µM |
With Tween |
219 +- 53 µM |
227 +- 51 µM |
Table with estimated K_M values
Results with substrate dependent enzyme inhibition¶
The fitting process is the same as for the standard Michaelis-Menten kinetic.
params = Parameters()
#params.add('k_cat', value=0.06, min=0.000001, max=1000)
params.add('v_max', value=0.6, min=0.0001, max=1000)
params.add('K_M', value=80, min=0.000001, max=10000)
params.add('K_i', value=160, min=0.000001, max=10000)
resultsSubstrateInhibitionNoTween = minimize(residual, params, \
args=('noTween', michaelisMentenWithSubstrateInhibition), \
method='leastsq')
resultsSubstrateInhibitionTween = minimize(residual, params, \
args=('tween', michaelisMentenWithSubstrateInhibition), \
method='leastsq')
Results for measurements without Tween
report_fit(resultsSubstrateInhibitionNoTween)
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 59
# data points = 7
# variables = 3
chi-square = 1.6757e-04
reduced chi-square = 4.1892e-05
Akaike info crit = -68.4802620
Bayesian info crit = -68.6425315
[[Variables]]
v_max: 0.73793858 +/- 3751.45850 (508370.02%) (init = 0.6)
K_M: 403.729434 +/- 2052481.20 (508380.37%) (init = 80)
K_i: 403.779136 +/- 2052761.60 (508387.24%) (init = 160)
[[Correlations]] (unreported correlations are < 0.100)
C(v_max, K_M) = 1.000
C(v_max, K_i) = -1.000
C(K_M, K_i) = -1.000
Results for measurements with Tween
report_fit(resultsSubstrateInhibitionTween)
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 59
# data points = 7
# variables = 3
chi-square = 2.1094e-04
reduced chi-square = 5.2735e-05
Akaike info crit = -66.8688780
Bayesian info crit = -67.0311475
[[Variables]]
v_max: 0.63003480 +/- 6550.46063 (1039698.22%) (init = 0.6)
K_M: 824.589609 +/- 8573114.67 (1039682.60%) (init = 80)
K_i: 824.458311 +/- 8571319.48 (1039630.43%) (init = 160)
[[Correlations]] (unreported correlations are < 0.100)
C(v_max, K_M) = 1.000
C(v_max, K_i) = -1.000
C(K_M, K_i) = -1.000
Visualisation of results
fig = plt.figure()
gs = fig.add_gridspec(1, 2, wspace = 0)
(ax1, ax2) = gs.subplots(sharey = True)
fig.suptitle('irrev. MM kinetic with inhibition')
sNoTween = []
sTween = []
vNoTween = []
vTween = []
for measurementData in dataDict['noTween']:
ax1.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
sNoTween.append(measurementData['s0'])
vNoTween.append(michaelisMentenWithSubstrateInhibition([measurementData['s0'],measurementData['p0']], \
resultsSubstrateInhibitionNoTween.params))
ax1.set(title = 'without Tween 80', ylabel ='initial rate [ '+concentrationUnit+'* 1/'+timeUnit+']', \
xlabel = 'ABTS concentration ['+concentrationUnit+']')
for measurementData in dataDict['tween']:
ax2.plot(measurementData['s0'], measurementData['v'], 'o', ms=3, color='#377eb8')
sTween.append(measurementData['s0'])
vTween.append(michaelisMentenWithSubstrateInhibition([measurementData['s0'],measurementData['p0']], \
resultsSubstrateInhibitionTween.params))
ax2.set(title = 'with Tween 80', xlabel = 'ABTS concentration ['+concentrationUnit+']')
ax1.plot(sNoTween, vNoTween, '-', linewidth=1, color='#e31a1c')
ax2.plot(sTween, vTween, '-', linewidth=1, color='#e31a1c')
# save as svg
# plt.savefig('initial-rates_irrev_Michaelis_Menten_inhibition.svg', bbox_inches='tight')
plt.show()
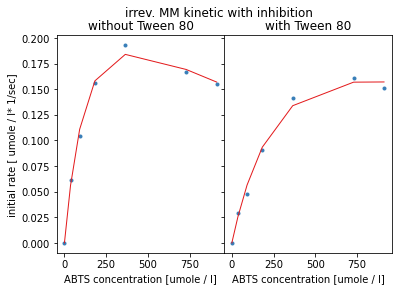
The modelled red curves show an optimum profile and seem to fit the given data points better than before. But the statistics of the estimated parameters show that no good fit was possible, relative errors are greater than fife thousand fold. This could be due to too few data-points for such a complex model. By comparing the quality criterion such as the Akaike information criterion which takes the number of parameters to be fitted into account, this second model has a lower criterion value and therefore better result.